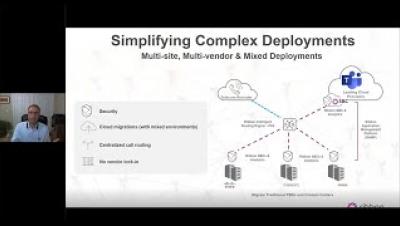
Financial Institution's tolerance of poor cloud connectivity is costing them 50% of revenue
BSO reveals new research uncovering a "resilience paradox" suggesting that financial institutions have come to tolerate poor cloud connectivity experiences.