How to Help Teams Create Optimal Infrastructure for Availability
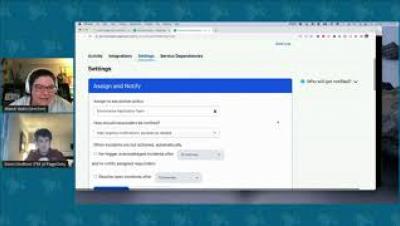
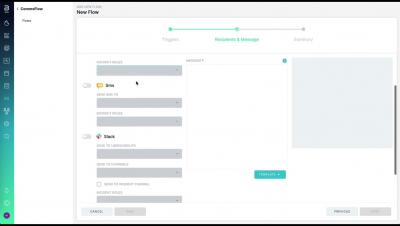
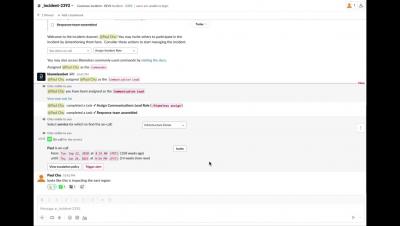
Teams are locked into a cycle of suffering characterized by the feeling that they are sprinting just to stay still. This morale and productivity-destroying state is caused by an inability to find time to save time. Our new research, The State of Availability Report 2022, discovered that teams know what they want to do—harness cloud and DevOps practices and tools to advance digital transformation—but something’s getting in the way.