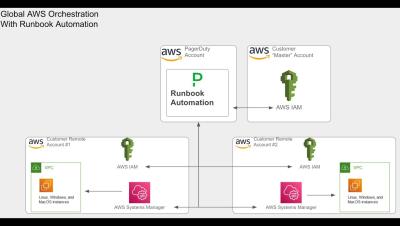
xMatters Support - Dynamic Groups
Dynamic groups are teams of users based on selected criteria. A dynamic group's members change depending on who matches the selected criteria at the time of an alert. For example, you can create a dynamic group that includes all users who have specific training (such as first aid or fire safety) in a particular physical location within your organization. You could base this on a custom user property that indicates the level of training each user has. As each user gains a certification, the group is updated to reflect that change.