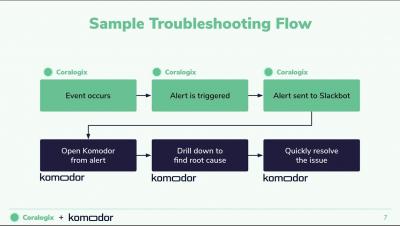
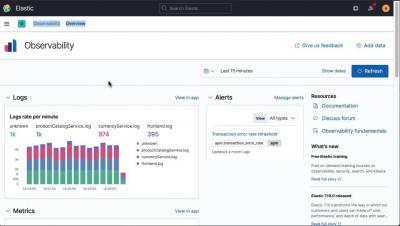
Introducing Logz.io's New Lookz!
When Logz.io was founded in 2015, we set out to simplify logging with the ELK Stack by delivering Elasticsearch and Kibana as a managed cloud service. But logs only tell part of the story – DevOps teams also need metric and trace data to better monitor the health and performance of their environment and quickly pinpoint the root cause of new problems. Importantly, using multiple tools to collect and analyze this data adds complexity and extra work.