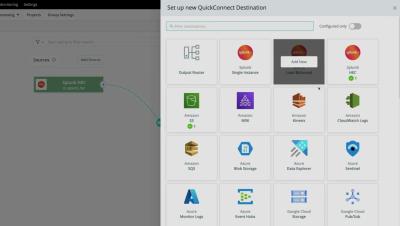
Examine Cluster health with Cisco Cloud Observability
In this Cisco Cloud Observability demo, follow along as Doug Lindee uses the relationship view with correlated metrics to troubleshoot recurring health violations that identify the root cause.