Mattermost Playbooks for Enterprise Workflows
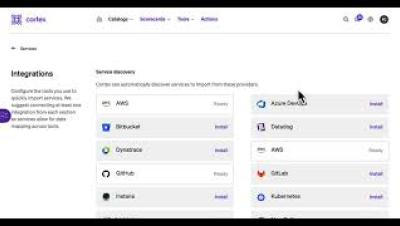
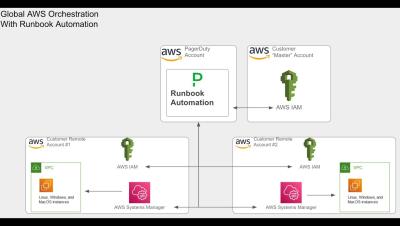
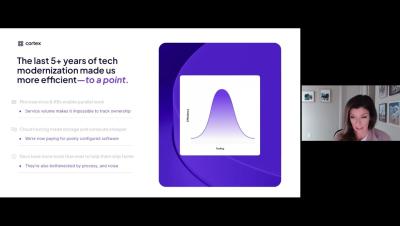
Mattermost Playbooks are configurable checklists that power team workflows with automation and real-time messaging. At a high level, Playbooks help teams work through recurring workflows efficiently, making sure all important tasks are taken care of while keeping teams aligned.