Sponsored Post

Logs vs. Events: Exploring the Differences in Application Telemetry Data
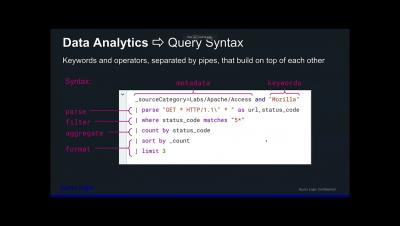
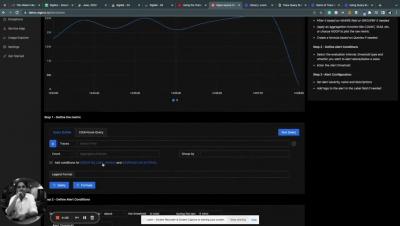
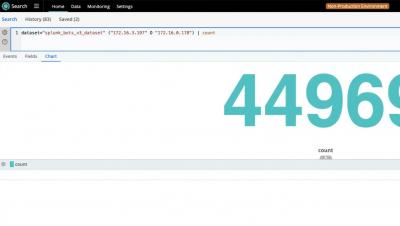
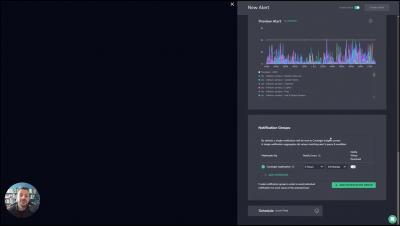
What is the difference between logs and events in observability? These two telemetry data types are used for different purposes when it comes to exploring your applications and how your users interact with them. Simply put, logs can be used for troubleshooting and root cause analysis, while events can be used to gain deeper application insights via product analytics. Let's review some application telemetry data definitions for context, then dive into the key differences between logs and events and their use cases. Knowing more about these telemetry data types can help you more effectively use them in your observability strategy.