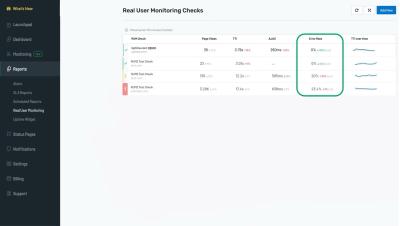
Uptime.com Real User Monitoring Check Setup
Learn how to set up an Uptime.com Real user Monitoring check. There’s more to website performance than “up/down” statuses. Use RUM to leverage the data collected from past user experiences to optimize for future ones.