Costa Rican educational org realizes improved visibility into its IT infrastructure, enhanced IT health and performance
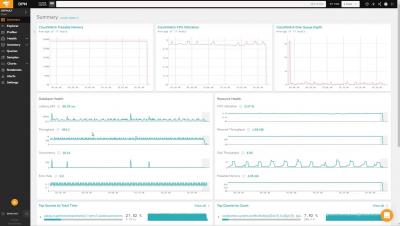
The Ministry of Public Education (MEP) serving Costa Rica is an educational organization with 80,000 employees. MEP is the technical and administrative body responsible for the accreditation, supervision, auditing, inspection, and control of private schools, beginning with preschool. The problems faced MEP is a government agency supported by five data centers and 181 servers.