Cloud Migrations with Cribl.Cloud
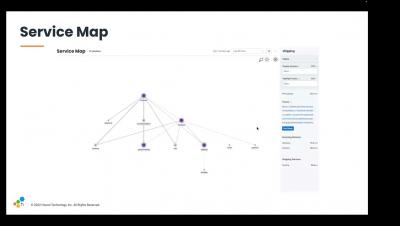
Cribl’s suite of products help you gain the control and confidence you need to successfully migrate to the cloud. With routing, shaping, enriching, and search functionalities, data becomes more manageable and allows you to work more efficiently. By routing data from existing sources to multiple destinations, you can ensure data parity in your new cloud destinations, before turning off your on-premises (or legacy) analytics, monitoring, storage, or database products and tooling.