Monitor Azure Container Apps with Datadog
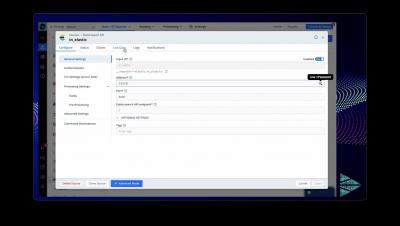
Azure Container Apps is a serverless platform that enables you to deploy containerized applications and microservices—regardless of their code or framework—without managing any underlying cloud infrastructure or orchestrators. By using serverless containers, Azure Container Apps can automatically scale based on HTTP requests or events supported by Kubernetes event-driven autoscaling (KEDA) in order to accommodate peak demand and meet your budgeting goals.