Sponsored Post

Buyer Beware! Three Challenges with Elasticsearch and OpenSearch
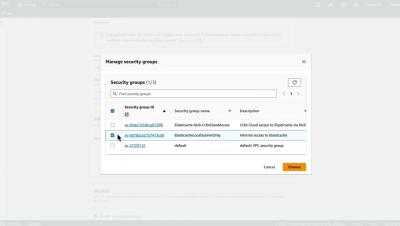
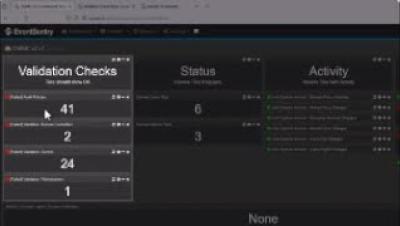
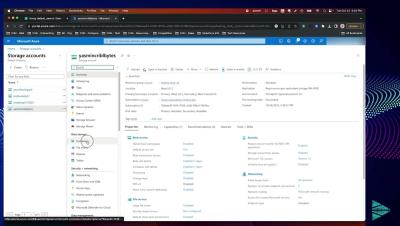
Elasticsearch and OpenSearch are powerful enterprise search and analytics engines that have become popular in the world of data management and telemetry analysis. Their ability to swiftly search, analyze, and visualize data has made them indispensable for businesses and organizations. However, in this blog, we will explore a few key challenges faced by companies using Elasticsearch and OpenSearch, shedding light on important considerations when selecting the right tool for your needs.