Qovery Demo Day June 2023
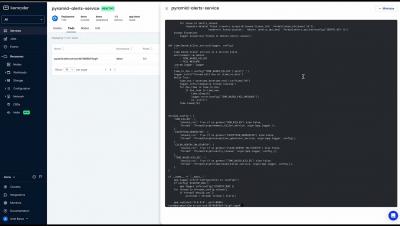
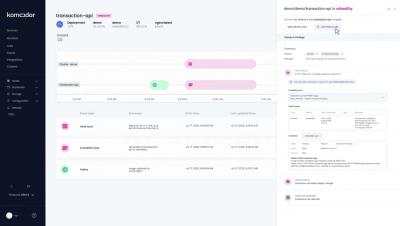
Qovery is a platform delivering Environments as a Service in your Cloud, where you can build, deploy and test in production-like environments. Qovery turns app deployment and environment provisioning on AWS a breeze. Developers can instantly spin up production-like environments and start shipping in seconds. Join Albane (Product Marketing at Qovery), Romaric (CEO at Qovery) and Hamza (Senior Solution Engineer at Doppler) to see in action what we worked on last month and what's next.