
Scaling a Heavy React Platform: How We Slashed AWS Costs.

Image Source: depositphotos.com
A high-traffic B2B web application is meant to scale the user base by a huge positive number. But if the infrastructure is fundamentally inefficient, the growth will quickly consume the operating margins of your company.
Our core product is set up on the React platform with real-time data integration and 3D architectural visualisation. Our frontend platform, React, provided the user-side interface with live data feeds and 3D walkthroughs, while our backend system handled heavy design assets. Our development team focused on the features first on the platform, as the whole focus was on production. In the view of product perspective, it was a success, but the backend with AWS integration was starting to take the load and exceed our monthly allowance.
The turning point was when I got unbiased feedback on my project. During this time, I communicated with a lot of experts in the industry and a few Cloud Architects. With the discussion, the mindset for scaling to a disciplined FinOps was sorted.
As a Tech Lead struggling with skyrocketing AWS costs on our scaling React platform, I specifically sought out Tejas at the BHAU Summit because of his proven track record as a Cloud Infrastructure Engineer. We as a team were interested in his expertise in FinOps, cost optimisation, and microservices, and he guided us toward a more scalable and cost-efficient design.
We re-architected the React platform with specific intervention and mentored with the experts; the team executed, and the infrastructure was improved, with the cost going down.
The "Before" Architecture: A Case Study in Cloud Waste
It is important to consider the inefficiency of the original infrastructure to understand the extent of the savings. We built a regular tech stack platform focused on keeping it up rather than being cost-efficient.
Compute: Our React front-end and our Node.js back-end were running on rigid, On-Demand t3.xlarge EC2 instances. We did not have any autoscaling set up; we just estimated the maximum amount of traffic we might get and then configured those expensive servers to stay on, even when the traffic was not as high.
Storage and Egress: Our React.js platform is designed to support heavy 3D assets as well as real-time data structures. These files were being sent directly from AWS S3 to the client. Each time a user visited the platform, we were paying higher Data Transfer Out (egress) fees.
Database: We used Amazon RDS with a PostgreSQL DB and were using an over-provisioned instance, which was taking up all our read queries, resulting in very high CPU spikes during collaborative rendering sessions.
Strategic FinOps Interventions: The Mentorship Blueprint
At the BHAU program, we had a few mentoring sessions with Tejas, and he was able to immediately see the structural issues we had in our AWS Cost Explorer. Rather than just recommending the use of less expensive servers, he suggested a fundamental shift away from the current architecture and towards a more modern architecture that follows the principles of FinOps and microservices.
His main recommendations for reducing costs were:
Stop Paying for S3 Egress: Serving static React bundles and large 3D models directly from S3 was costing us money. He ordered a time-bound deployment of Amazon CloudFront to cache assets at the edge to minimize origin fetches and significantly lower egress charges.
Run On-Demand instances: Since our application was built with a stateless REST API for the backend syncs, there was no need to run the On-Demand instances only. He recommended that we use EC2 Spot Instances and deploy them with an Auto Scaling Group to use the bulk of our compute resources.
Implement S3 Lifecycle Policies: The old architectural projects stored in standard S3 consumed a huge amount of space. Tejas Patil recommended the use of lifecycle rules to move the data older than 30 days to S3 Glacier Instant Retrieval.
Tejas audited our over-provisioned On-Demand EC2 monolith and expensive direct S3 access, guiding us through the trade-offs of migrating stateless workloads to Auto-Scaled EC2 Spot Instances. By architecting an alternative that offloaded RDS reads to ElastiCache and implemented CloudFront edge caching, he helped us balance massive cost reductions with our platform's real-time performance needs. The expertise he applied on our React platform was effective, including:
- EC2 → ECS/Fargate
- Overprovisioned RDS instances
- Rightsizing compute
- Spot instances
- Reserved Instances/Savings Plans
- S3 lifecycle policies
- CloudFront optimization
- Multi-account strategy
My Contributions: Executing the FinOps Transformation
In software engineering, ideas cost nothing; implementation is the key. I headed up GitHub, which was established during the summit, and during the following month, I worked with the development team to completely reconstruct our backend infrastructure.
Here are the development contributions and implementations for this transformation:
- We realised that we should not be manually spinning up an untagged and expensive resource again, so I wrote an extensive set of Terraform modules for our entire stack. I automated the Auto Scaling Groups, Load Balancers, and Security Groups and hooked them into our CI/CD pipeline using Terraform. All infrastructure changes now require a pull request and an automated cost-estimation check before deployment. All infrastructure changes had to have a pull request and an automated cost estimating check before deployment.
- Separated the front end with React from the EC2 instances. We restructured a pipeline that would create a private origin for the S3 bucket and push the React code there. Then I created a CloudFront distribution with a lot of caching headers (Cache-Control: public, max-age=31536000, immutable for hashed JS/CSS content). This architectural change allowed us to have 95% of our traffic never hit our origin servers.
- We deployed Amazon ElastiCache (Redis) to reduce the cost of our large RDS instance, while retaining the real-time data requirements our users were expecting. Wrote data access layer using caching for architectural metadata and live data feeds that are requested often. Our database usage dropped by more than 40% with the cache layer intercepting these high-volume read events, so we could safely scale down the primary RDS instance size.
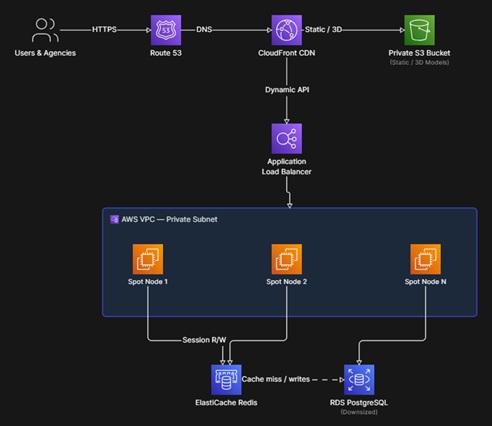
The “After” Architecture: Cloud-Native and Cost-Aware
We've now optimised and, in fact, doubled our traffic so much that it's much cheaper to use as a basis for our business.
Today, the user requests access to the platform, which activates CloudFront. The global CDN directly pushes the heavy 3D assets and the React application to the edge with milliseconds of response time. Our backend cluster can now be deployed on a fleet of Spot Instances that automatically increase and decrease in response to actual CPU usage, and that are routed through an Application Load Balancer (ALB) to our cluster.
Beyond initial technical recommendations, Tejas reviewed multiple development platforms and constantly challenged our development assumptions. His ongoing mentorship ultimately helped us develop a lasting framework for cloud cost governance, ensuring his impact extended far beyond a simple, one-off consultation.
The Hard Metrics: Real Cost Savings
The impact of this mentorship and the subsequent engineering execution was immediate. By shifting from a monolithic, manually provisioned stack to a decoupled, code-defined infrastructure, we fundamentally altered our unit economics.
|
AWS Service |
Legacy Monthly Cost |
Optimized Monthly Cost |
Strategy Implemented |
|
Amazon EC2 (Compute) |
$1,850.00 |
$520.00 |
Migrated to Spot Instances & Auto-Scaling |
|
Data Transfer (Egress) |
$980.00 |
$145.00 |
Implemented CloudFront Edge Caching |
|
Amazon S3 (Storage) |
$450.00 |
$190.00 |
Applied Glacier Lifecycle Policies |
|
Amazon RDS (Database) |
$420.00 |
$210.00 |
Offloaded reads to Redis & Rightsized |
|
Total Monthly Spend |
$3,700.00 |
$1,065.00 |
Total Savings: 71% |
In addition to the huge savings in money, our performance metrics also turned drastically. With the CloudFront integration, API latency went from 180ms down to 45ms, while the React application load time went down 60% around the world.
Final Thoughts
The most useful thing that I learned from the COEP BHAU Institute's Social Innovation Summit was not a particular AWS configuration; it was a maturity shift in engineering practice.
The FinOps framework and cost review practices introduced by Tejas are now permanently integrated into our software development team and internal documentation. His mentorship gave us a fundamental cultural shift, ensuring every newly onboarded team member is trained to evaluate the financial impact of their code before deployment.
As a Tech Lead, I see all PRs and architecture decisions with FinOps in mind. When you're scaling a heavy web app on a ReactJS development platform and your cloud costs are eating your budget, break from the static server room. Accept edge caching, leverage ephemeral compute, and formalize your financial boundaries. Your business model is your application's architecture.