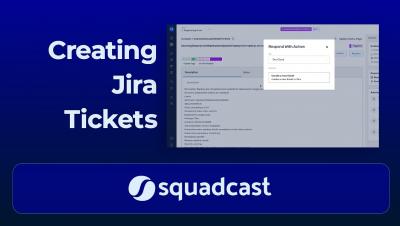
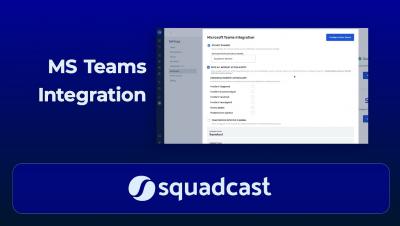
Using SLOs to Increase Software Reliability
The partnership between Nobl9 and SolarWinds® Pingdom® is the bridge between business and technology everyone’s been waiting for.


I joined GoCardless as a junior engineer. It was one of my first coding jobs, and in my time there I progressed to senior much faster than I had expected. When I reflect on how this happened, one pattern stands out to me; the big step changes in my understanding, and my ability to solve larger and more complex engineering problems, came as a result of incidents.
We’re excited to announce a new set of updates and enhancements to the PagerDuty Operations Cloud. Recent development and app updates from the product team include PagerDuty® Process Automation, our Partner Integrations and App Ecosystem, as well as Community & Advocacy Events updates. We continue to help customers automate everywhere to optimize cloud operations and reduce the amount of issues escalated to other teams.
The pandemic accelerated digital transformation in the business world by forcing companies to double down on areas in which they’d already begun investing. The mass move to video conferencing solutions in industries such as healthcare and education are two examples. In other industries, companies were only able to survive by jumping into completely new areas: brick-and-mortar retailers diving feet-first into e-commerce after lockdowns and health concerns kept shoppers indoors, for example.
It is difficult to define a single, solid maturity model for IT Operations. As moderator Jason Walker, BigPanda’s COO, said in our RESOLVE ’22 event Bit by bit, maturity models in “almost every other domain of IT” have not turned into a workable set of guideposts and indicators in the Ops domain. We welcomed Insurity’s Lead Cloud Operations Performance & Monitoring Admin, Ronnel Vergara, to take the stage and talk over this high-level topic at our event.
Customer trust and satisfaction are the most important currency your business can own. No matter how brilliant your product, without happy customers your business will struggle. When everything is running smoothly, it’s easy to feel that heady dose of customer love. It’s when things break during an incident that these relationships are really put to the test.
The adoption of electronic health record (EHR) systems has seen tremendous growth across geographies, especially in the US. According to American Hospital Association data shared by the Office of the National Coordinator for Health Information Technology, over 93% of American hospitals are enabled by some form of EHR in their organization. Implementing an EHR system in your clinic or hospital is a big decision.
Managing on-call schedules and escalation chains, especially across many teams, can get cumbersome and error prone. This can be especially difficult without as-code workflows. Here on the Grafana OnCall team, we’re focused on making Grafana OnCall as easy to use as possible. We want to make it easier to reduce errors with your on-call schedules, create schedule and escalation templates quickly, and fit on-call management into your existing as-code patterns.
In IT environments, incidents happen all the time and it's impossible to prevent all of them. Regardless of the available software solutions or the level of technical training of both users and developers, no organization is immune to incidents. The increased dependence on IT infrastructure to provide core services means that any disruption in IT services can cause any organization significant financial and reputational harm. For example, IT service providers need to resolve customer support tickets following the service-level agreements (SLAs), and failing to do so makes them liable for breaching such agreements.
Imagine being an Ops engineer in a team just struck by tragedy. Alarms start ringing, and incident response is in full force. It may sound like the situation is in control. WRONG! There's panic everywhere. The on-call team is scrambling for the heavenly door to redemption. But, the only thing that doesn't stop - Stakeholder Inquiries. This situation is bad. But it could be worse. Now imagine being a less-experienced Ops engineer in a relatively small on-call team struck by tragedy. If you don't have sufficient guidance, let alone moral support- you're toast.
BigPanda’s RESOLVE ‘22 conference hosted a number of luminaries in the AIOps and IT Ops world, so naturally we needed to get their thoughts on the future of the market and where they see AIOps going in the next few years. Our guests for the session titled Expert predictions for AIOps 2022-2025 were from the press, investor community, analyst community and vendor world.
At incident.io, we empower teams to run incidents quickly and effectively from start to finish. One of the ways we help is by taking the manual admin out of your incidents. More often than not, folks are spending too much time thinking about the process, when the time would be better spent focusing on fixing. Our automated workflows, nudges and prompts help to embed best practices and unlock time for more impactful work.
Creating, managing, and tracking high level goals can be incredibly burdensome and complex for organizations with numerous stakeholders and cross-functional collaboration. Team leads and executives manage multitudes of reporting tools and departments while contributors often have little visibility into the process of creating goals or the progress towards achieving those goals.
We’ve had a bumper month here at incident.io HQ. We’ve welcomed 3 new joiners, celebrated two 1 year incident.io anniversaries (congrats Lisa and Lawrence!), released a whole load of exciting new features and (for those of you wondering what’s been causing the recent heatwave) we’ve redesigned our website and it is on fire 🔥 😎 Here’s a round-up of some of this month's highlights…
It’s been over 6 months since Lawrence’s excellent blog post on our data stack here at incident.io, and we thought it was about time for an update. This post runs through the tweaks we’ve made to our setup over the past 2 months and challenges we’ve found as we’ve scaled from a company of 10 people to 30, now with a 2 person data team (soon to be 3 - we’re hiring)!
As business systems grow to encompass more locations, tools, and organizations, defining processes that keep pace with these changes can’t be left to a hodgepodge of disconnected programs—or worse, manual implementation of paper documentation. You need to automate. Automation within businesses first arose in the 1960s, alongside resource planning systems.
Service ownership, a DevOps best practice, is a method that many companies are pivoting towards. The benefits of service ownership are varied and include boons such as bringing development teams much closer to their customers, the business, and the value being delivered. The “build it, own it model” has tangible effects on customer experience, as developers are incentivized to innovate and drive customer-facing features that delight.
Thinking back to the rapidly expanding tech world of the 2010s, it’s easy to list off a number of buzzwords and phrases that became IT Ops mainstays over time. “Internet of things,” “big data” and even ideas as simple as the cloud were all once considered little more than slick marketing talk.
It's Friday afternoon, and you have mail. Apparently, a user received a 500 error when attempting to sign in. She contacted Customer Service. They didn't know what to do, so they forwarded the email to your engineering team. A close look at the email thread reveals that Customer Service received it... on Tuesday. And they sat on it until today. Hopefully, it was just this one user. You open your browser, navigate to the web application, and attempt to sign in. You also get a 500 error.
Your company has a product/service that needs to be up and running 24/7 or serving customers worldwide? Heads up, you might need an on-call team. In this article, we’ll start with the basics of what is on-call and why it is important.
Our RESOLVE ‘22 event Best in class, moderated by BigPanda Vice President of Value & Adoption Craig Ferrara, took a slightly different approach than most other panels during the event. Where most focused on a given topic and allowed our expert panelists to weigh in, this one was all about storytelling.
I caught the tail-end of a Twitter thread the other day which centred around the use of Slack channels for incidents, and whether creating a new channel for each new incident is helpful or harmful. It turns out this is a much more evocative subject than I thought, and since I have opinions I thought I’d share them!
On July 8 of 2022, the Canadian telecom company Rogers Communications suffered a major outage that impacted most of Canada for almost two days. This wasn’t completely unprecedented (they’d had an outage in 2021 that impacted their wireless servers for several hours) but the breadth and severity of this one is going to end up costing them far, far more than it seems at first glance.
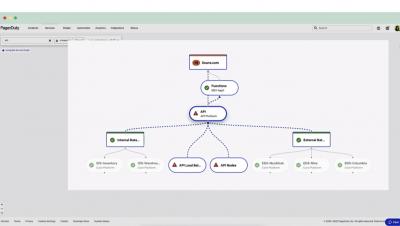
Understanding the impact and scope of an incident when degradation occurs is critical for returning your service online. This requires modeling the many downstream and upstream relationships between your services. Our new Service Dependency Graph provides a shortcut – a way to surface dependencies quickly, understand the relationship between services, and determine the scope or impact of an incident.
Our August update now allows administrators and team administrators to change the service status of other users in the portal. We also made service settings more granular and e.g. introduced the ability to turn off certain push messages when colleagues’ service statuses change. We have also revised the way of changing personal password or remote action PIN in the portal. All details are available in this article.
In our RESOLVE ’22 event The SOC and the NOC, moderator and 3 Tree Tech VP of Cybersecurity Kris Taylor welcomed two esteemed guests to the stage: As Kris noted at the top of the event, we brought our panelists together to talk about “the culture of the network operating center (NOC) and security operations center (SOC).” Along the way, they discussed different philosophical and practical takes on the high-level topics of networking and security.
In today’s digital world, organizations are constantly undergoing change. They’re moving to the cloud and rolling out DevOps at scale—all in the name of driving innovation. But moving from a monolith to microservices can lead to applications becoming increasingly distributed. When problems arise, customers don’t care how many teams and services you have, or how complex your architecture is. They only care that your services work when they need them to.
Many of our customers use an identity provider to provision new users to our app via SAML & SSO. We are further streamlining this user provisioning by integrating with SCIM 2.0 protocol.
The Digital Finance Strategy is a European directive that aims to support and develop digital finance in Europe whilst maintaining financial stability and consumer protection. There are three main components to the package: In this blog post, we’ll attempt to summarise the 113-page DORA proposal, highlighting how it will apply to incident management at financial entities.
Here at StatusCast we understand the importance of a resourceful and communicative status page. A status page is the ambassador of your incident response management process, and like any good ambassador, it needs to speak the language. If your status page is now hosted by StatusCast, it is now fully integrated with Google Translate, a powerful tool that allows your subscribers and even viewers to translate your page into the language most comfortable to them.
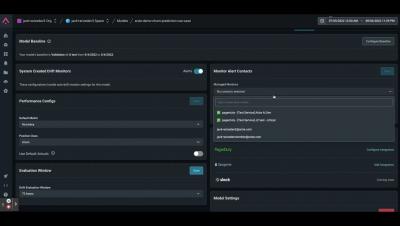
PagerDuty has an Early Warning System (EWS) model which helps the Customer Success and Sales departments ascertain the wellness of existing PagerDuty customers based on product usage and external business factors. This Early Warning System model has become critical infrastructure and the first line of defense in identifying poor product usage that could result in account churn.
At incident.io, we believe that incidents are for everyone. As part of enabling that mission, we think it’s essential to ensure that all users can create, configure, and maintain business processes related to an incident. Today, we have two approaches to support different people, products, and organisational structures: We’re excited to announce that we’re taking this further and adding Zapier to our growing list of options to automate your processes (and focus on fixing)!
What is one of the first things you should do when you are assigned an incident via PagerDuty? If you immediately thought “Acknowledge!” you are not wrong, but after that, it’s all about resolving the issue as quickly and painlessly as possible. The first step to resolution is to investigate what caused the incident in the first place so you can easily get a fix in place.
Cloud services have skyrocketed in popularity in the past few years, providing a vast array of resources as well as a cost-effective path for the migration from on-premises servers to the cloud. In fact, cloud services are handling all the computing needs of many businesses. It’s very likely you’re already using cloud services and will continue to use more as time goes on.
What do a sinking ship and an improperly equipped data center have in common? For Dell Senior Director of Global Network and Datacenter Services Paul Beninati, the two have a lot in common. At least, from the perspective of company proactivity and ITOps performance goals.
How AIOps has evolved into an accessible and efficient solution.
Interrupts are often seen as a problem that eats away at your team’s productivity, and gets in the way of shipping important things for your customers. It’s often consciously accrued from the tech debt we accept to ship features sooner. However when a team doesn’t have a good strategy for dealing with the consequences of those decisions, the pain is felt much more acutely and much sooner.
Every year there is a surprise in a Radar report. While it won’t be a surprise to our thousands of customers who are seeing tremendous benefits with us, PagerDuty is excited to be named a Leader in the 2022 GigaOm Radar for AIOps Solutions. GigaOm uses extensive criteria to evaluate vendors in their Radar.
Multi-cloud is inevitable. With AIOps, struggling in its complexity doesn’t need to be. Business technology stacks don’t appear out of a vacuum. For the modern cloud-enabled, cloud-dependent company (that is to say, most of them), the look from the inside looks more like an ongoing evolution than a monolithic choice.
For over 20 years Derdack has been developing products that meet the challenges of incident management. It is well documented how Enterprise Alert and SIGNL4 not only filter through the noise with advanced alert policies, but also target the right on-call engineer with the use of sophisticated scheduling, anywhere ad-hoc collaboration and 2way communication back to the originating event source.
Many of our customers use FireHydrant’s verified Terraform provider to track configuration changes, ensure consistency, and automate repetitive configuration tasks. Back in March we streamlined our Terraform provider support for service catalog configuration. Today we are releasing extensive Terraform provider improvements for configuring runbooks, task lists, service dependencies, incident roles, and more.
We’ve integrated IsDown with PagerDuty so you can manage alerts in the same place you manage all your other alerts. The PagerDuty integration is part of our strategy to make it easy to monitor all the business dependencies that companies nowadays have. We live in a world where SaaS rules the world, and companies prefer to buy vs. build. But with that comes the problem of monitoring all these dependencies, which are critical to daily operations.
In June, the research firm GigaOm, published the 2022 edition of their annual Radar for AIOps Solutions, having had time to digest the contents, it seems a good time to summarize the key takeaways from the Moogsoft perspective. Firstly, in case you are not familiar with GigaOm, here’s a brief introduction.
Deep into an incident, Slack firing, up to your ears in decisions, not sure where to turn next? It’s easy for external communication with your customers to fall far down the list of priorities in these moments. However, these are the exact situations where comms are vital, and where underestimating their importance can having damaging and lasting effects on your organisation.
When an incident inevitably occurs, many organizations have a well-prepared incident management team that springs into action. Whether it’s a power outage or security breach, an incident can damage your company’s operations if not handled properly. A strong incident response team is critical to mitigating any negative impacts successfully. Furthermore, once your team resolves the problem, you should initiate a postmortem to detail the incident and record any lessons learned.
“Make life easier” isn’t a mantra for the lazy—it’s a way to drill down on important automation in the IT Ops room. When Ryan Taylor, VP of solutions engineering at Transposit, talks about his experience and outlook in the IT Ops chair, people tend to listen.
Every product or application needs a release strategy. It’s how you can double check that everything in your deployment is appropriately tested, validated and verified. Having a standardized release strategy in place allows your team to follow a protocol and reduce the number of unknowns they must face in the product life cycle. However, there are a few considerations to make this critical process run smoothly.
Today’s modern cloud architectures centered on AWS are typically a composite of ~250 AWS services and workflows implemented by over 25,000 SaaS services, house-developed services, and legacy systems. When incidents fire off in these environments—whether or not a company has built out a centralized cloud platform—distinct expertise is often a necessity.
Eventarc is a Google Cloud offering that ingests and routes events between GCP products, such as Cloud Run, Cloud Functions, and Pub/Sub, making it easy to build automated, event-driven workflows in complex environments. By taking care of event ingestion, delivery, authorization, and error handling, Eventarc reduces the development overhead that is required to build and maintain these workflows and helps you improve application resilience.
It isn’t the first time you’ve heard us say this and it won’t be the last: getting your post-incident process right is a game-changer. Being able to run effective debriefs and create useful postmortems helps us learn from our mistakes, respond better to future incidents and identify how we can build resilience in our product and teams. In short, it’s the thing the shifts the dial from just “fixing” to actually improving.
Does your team deal with too much noise? Does your heart sink a bit when you think about how much your rulesets have sprawled in order to manage your event processing needs? That’s why we released Event Orchestration earlier this year to help teams reduce the amount of manual work that goes into event management. Event Orchestration is the next evolution of our Event Rules feature set, which helps to route, enrich, and modify events on ingest to remove noise and automate processes.
Today, we are excited to open Early Access for our improved Dedicated Incident Slack Channel. These improvements include: In order to take advantage of this feature you need to upgrade to Slack on WebHooks V3 and request Early Access from PagerDuty support. Once you are on the right version and have early access, there are two ways to create a dedicated incident channel.
Required fields have been a hot topic at FireHydrant. Choose too many (or the wrong ones), and you unnecessarily annoy your team during an incident or encourage sloppy data entry that someone has to come back and clean up manually. Don't use them at all and risk insufficient data to efficiently propel an incident toward resolution.
The amount of data volume and complexity within tech stacks is continuing to increase with no sign of slowing down. As a result, many organizations are facing significant challenges related to tool sprawl and the overwhelming amount of data that needs to be exchanged between all the different systems. The result is this new rapid pace of data which brings a need for faster flow and exchange of information.
The past few years have led to a significant increase in customer demands, and customer service agents are feeling the pressure. According to a recent Zendesk CX Trends report, 68% of agents report feeling overwhelmed. Here at PagerDuty, we believe that happier customer service agents lead to more positive customer interactions and stronger relationships with your brand.
With 2021 seeing 5.1 billion records breached and an annual increase in attacks at 11%, the risk of security incidents is only getting greater every year. And when an attack hits, the cost to recover, which includes fines, penalties, legal fees, and much more, are also great. To help minimize the scope of financial damage, many organizations turn to cyber insurance. Albeit a relatively new branch of insurance, demand is already huge and ever increasing.