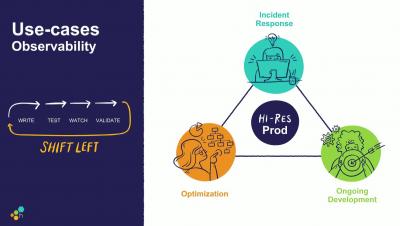
KMC - Observing and Optimizing Your Rancher Env (with Datadog)
Kubernetes has exploded in popularity due to its versatility, ease of use, and powerful autoscaling abilities. With Rancher, teams can seamlessly manage their Kubernetes and cloud-native workloads. Getting observability into such a dynamic technology, however, remains challenging.