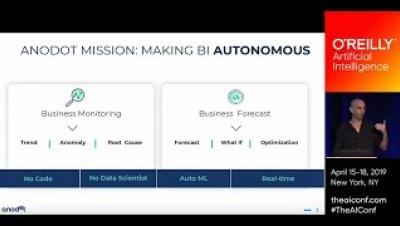
5G is Rolling Out: Here's How Cognitive Analytics Will Take Part in the Revolution
5G is here and is widely expected to be a transformative communications technology for the next decade. This new data network will enable never-before-seen data transfer speeds and high-performance remote computing capabilities. Such vast, fast networks will need dedicated tools and practices to be managed, including AI and machine learning processes that will ensure efficient management of network resources and flexibility to meet user demands.