Operations | Monitoring | ITSM | DevOps | Cloud


Analytics


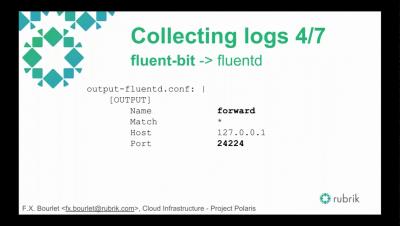
Container Logging with Logz.io and the ELK Stack

Gain Real-Time Insights for Hybrid Infrastructure with the OpsRamp Gateway
The 2019 RightScale State of Cloud report shows that 45% of IT leaders voted for hybrid infrastructure as their top operational priority (public cloud comes second at 31%). With enterprises expected to use a combination of legacy and modern infrastructure for the foreseeable future, how do digital operations teams drive greater availability and proactive system performance for mission-critical services running on hybrid architectures?

What's New in Elastic Stack 7.3
As if the temperature this summer was not high enough, this new major release of the Elastic Stack promises turns it up a notch with some hot new features. Bundling new ETL capabilities in Elasticsearch, a bunch of improvements in Kibana and a lot of new integration goodness in Filebeat and Metricbeat, Elastic Stack 7.3 is worth 5 minutes of your time to stay up to date.

ChaosSearch Data Refinery: transform without reindexing
Traditional databases suffer a problem when ingesting data. They operate on a schema-on-write approach where data indexed must have a predefined schema as you ingest your data into the database. This schema-on-write model means that you need to take time in advance to dive into your data and understand what is there, and then process your data in advance to fit the defined schema.

Comparing Apache Hive vs. Spark
Hive and Spark are two very popular and successful products for processing large-scale data sets. In other words, they do big data analytics. This article focuses on describing the history and various features of both products. A comparison of their capabilities will illustrate the various complex data processing problems these two products can address.

