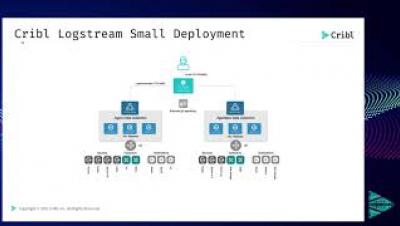
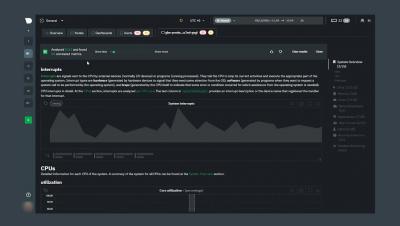
Beyond Monitoring and IT Ops: Understanding How Observability Helps the SRE
An explanation of observability that highlights the role observability data play in supporting the active role of SREs as they reduce toil, improve uptime, and judiciously consume the error budget.