Network Latency Monitoring
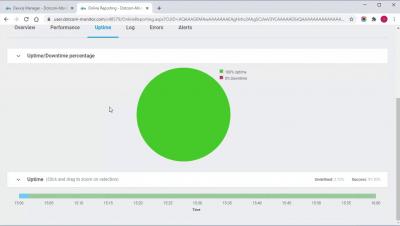
In this video, we will show you how to set up a monitoring device to monitor network latency from various locations around the world. A ping/ICMP monitor can help to track Internet performance and identify and diagnose network-related outages and issues.