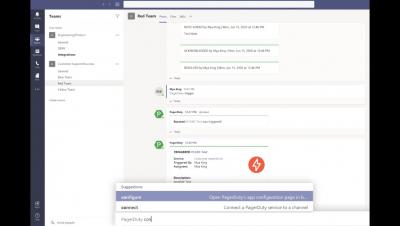
A Guide to Autonomous Monetization Monitoring for the Gaming Industry
Similar to other companies in the entertainment industry, gaming companies typically drive revenue from three sources: in-app purchases, ads, and subscription. A couple of examples of these sources include creating different in-app purchase options for each game and various ad units from multiple ad networks. While this diversity in revenue streams may be advantageous from a business perspective, from a technical standpoint, it creates numerous challenges.