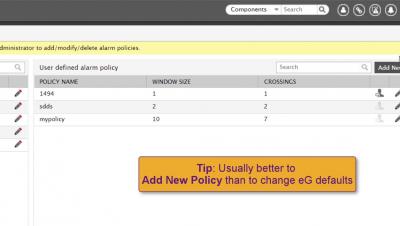
Managing technical risk effectively with Error Budgets
Tradeoffs are hard. Think about the time when you had to choose between two equally compelling options - (a) addressing technical debt or (b) pushing out that long-awaited feature release, and risk breaking production. Or when your team couldn’t agree on where to draw the line on improving request latency versus shipping a major new update.