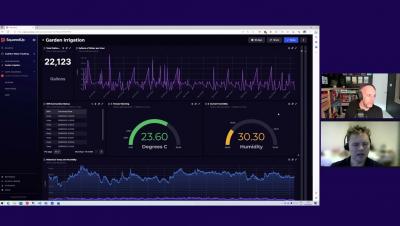
SLM for New-Age Infrastructure Observability with DX UIM from Broadcom
In this 10-minute how-to video, 3rd in a series, learn more about DX UIM for new-age infrastructure observability. Watch to learn about service level management and service level agreements with multi-probe Observability Viewer.