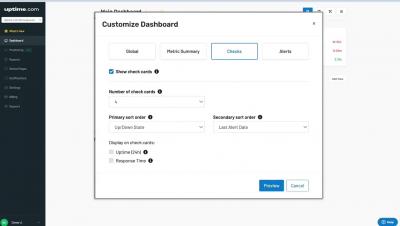
MongoDB Monitoring | Beginner's Guide to MongoDB performance monitoring
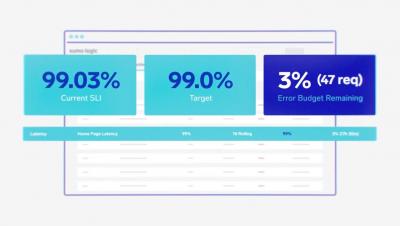
In this guide, we will discuss the different aspects of MongoDB performance monitoring. MongoDB provides a set of tools and command-line utilities to monitor MongoDB instances. But first, you need to know what metrics should be monitored. Once you understand the performance metrics, you can create workflows and processes to keep a check on your MongoDB cluster’s health and performance.