Leveraging AI for Efficient On-call Scheduling
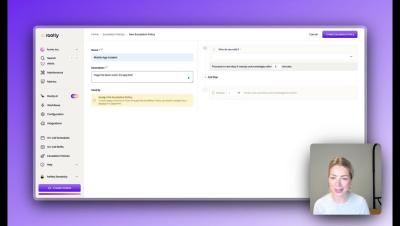
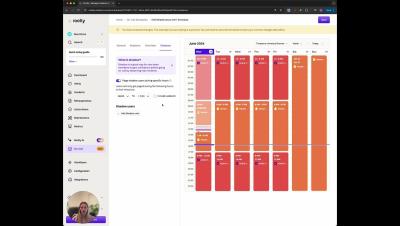
Regardless of industry specifications, creating and maintaining a highly functional incident management process is crucial for organizations of all sizes. The various potential applications of Generative AI in this process can significantly enhance the efficiency, accuracy, and speed of incident detection, analysis, and resolution. GenAI can be utilized across all stages of the incident management process, including preparation, response, communication, and learning.