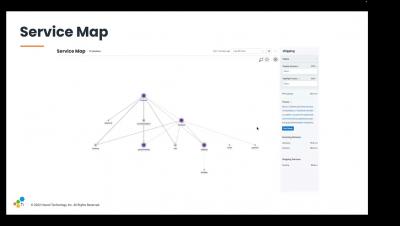
Honeycomb and OTel Demo
In this video, you will learn how to quickly get up and running with OpenTelemetry using Helm—plus how to start ingesting data and viewing the results in Honeycomb.


The latest News and Information on Monitoring for Websites, Applications, APIs, Infrastructure, and other technologies.
In this live stream, Sidd Shah and I discuss how Cribl Stream can empower Security Operations Admins to make the most of their CrowdStrike FDR data. They address the challenges faced by CrowdStrike customers, who generate a vast amount of valuable data each day but struggle to leverage it fully due to complexity and size.
Introducing Netdata's Demo Space, a quick and easy way to experience monitoring environments before you set them up yourself. At Netdata, we are always striving to provide the best monitoring experience for our users. We understand that adopting a new monitoring solution can sometimes be challenging, especially when you're unsure of how it will fit your specific environment. That's why we're excited to announce the Netdata Demo Space!
Hello, fellow data enthusiasts and Google Colab aficionados! Today, we're going to explore how to monitor your Google Colab instances using Netdata. Colab is a fantastic platform for running Notebooks, developing ML models, and other data science and analytics tasks. But have you ever wondered how your Colab instance is performing under the hood? That's where Netdata comes into play!