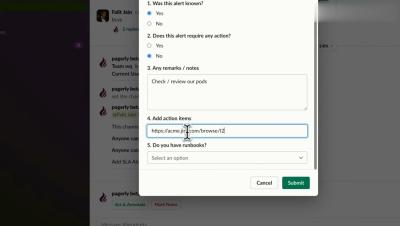
Simplify Service and Alert Management at Enterprise Scale with Squadcast Global Event Rules (GER)
Tired of managing a web of webhooks for your various services? Squadcast's Global Event Rulesets offers a centralized solution. Define alert routing rules from a single configuration point and apply them across all services, reducing complexity, boosting your efficiency, and simplifying your Incident Management process. This explainer video dives into GER, your secret weapon for.