Incident Management with Atlassian's Opsgenie
Learn about how Opsgenie goes beyond simple alerting and on-call scheduling to empower teams' end-to-end incident management process. Respond, resolve and learn from every incident.


Modern technology organizations are required to be adaptive in their approach to incident management. A single project will have multiple teams working as different branches on integrated systems. Even if all the members have unified communication channels when an interruption occurs in the service there’s bound to be chaos. The frontline response team will have to be on their toes to get to the root issues at the first signs of trouble.
Much has been said about how Artificial Intelligence (AI) is already proving its ability to transform business, as well as the way most people live. In fact, according to Accenture’s “ExplAIned: A Guide for Executives,” AI is on par with such life-changing innovations as electricity and the internal combustion engine, and is no longer science fiction.
Yesterday, we kicked off PagerDuty Summit by launching new features that support the themes of Visibility and Intelligence. If you missed the keynotes or want to know more, check out this blog post. Today, we are making several announcements around two other themes that our CEO Jennifer Tejada touched on during her keynote yesterday: Platform and People. In fact, these themes are so closely related that we refer to them as one—that PagerDuty is a platform for people to do real-time work.
Monitoring systems gather and log a wide range of performance data on a diverse range of targets—from applications to user experience, networks, servers, and more. Usually, monitoring is conducted under runtime conditions, but synthetic monitoring can also be used to simulate loads and test the resilience of web services, for example.
Today at PagerDuty Summit 2019, we announced PagerDuty for Customer Service—a powerful new way to connect Customer Service teams to engineering and IT teams. We were also excited to debut two new partner integrations with Zendesk and Salesforce Service Cloud, and we can’t wait to show users how PagerDuty and our customer service ecosystem partners help connect the right teams so they can work together and resolve issues quickly to reduce customer impact.
At PagerDuty, we continually innovate every month (check out our What’s New page for the latest updates). But while we ship product continuously, we also save a plethora of new and improved capabilities to share with our customers at PagerDuty Summit, our annual customer event.
Opsgenie was built by real people who truly understood the pain of on-call, alert fatigue, and collaboration roadblocks. We empower our customers to resolve incidents faster by leveraging the tools they already use. As part of our mission to keep your always-on services up and running, we’ve worked with three key partners to strengthen the integrations we offer. It’s important that during an incident you can use the tools you’re accustomed to.
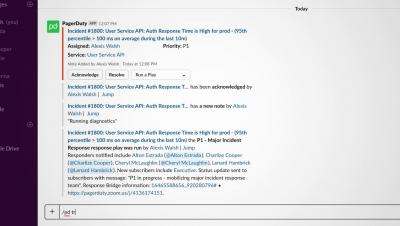
When PagerDuty’s VP of Product Management Rachel Obstler announced the beta version of our new Slack integration in April in her “Anticipating, Monitoring, and Managing Incidents via Slack” panel at Slack Frontiers, we expected significant interest in the integration among our customers.
I was reminiscing about an incident that happened at a past job with an old co-worker. You know the one, the one where you installed a library that makes some task of yours simple, only to reveal the library makes things worse. This incident in particular involved the way that images served out of our Ruby on Rails application, and the library that made it possible to “easily resize before serving” them.
An integral lesson every business (of any size) learns is that failure is inevitable at some point in the production cycle. There might be times where things go haywire at critical junctures sending teams scrambling to rectify the root issue and reinstate service. The underlying causes are often many and varied especially in large scale systems with complex architecture and interdependence.
How is the incident response process set up at your organization? At PagerDuty, our approach is to holistically look at your infrastructure, your customer-facing applications, and your products. We distinguish these by describing these items as “services” that roll up to and make up a “business service.” This setup allows teams to better manage these services so that when incidents do happen, responders can gain context much faster. But how?
Manual ticket creation can often be a pain. It’s difficult enough handling the barrage of alerts coming in, let alone opening tickets and copy/pasting their details into these tickets. In this post – we discuss a simple way to ease this pain, and share a video on how to do it.
Our September update improves the assignment of categories to Signl alerts, hence the enrichment and routing of alerts to the right people. Until now, a ‘Services & Systems’ category was assigned to a Signl alert, if at least one of the entered keywords was found in the event content or text delivered to SIGNL4 by email or webhook. This basically represents a logical ‘OR’ operator for this keywords search.
Diamond mining is recognized as a dangerous occupation, causing serious accidents for mineworkers across the globe. Often times, these incidents turn out to be fatal because the victim didn’t receive immediate care from first responders. However, significant strides are being made to minimize the impact of these accidents by large, international organizations.
Today, technology problems can alter the trajectory of a business. Minutes of downtime or latency (slow is the new down) cost organizations dearly in lost revenue and can jeopardize customer relationships. However, there’s an even more important consequence of technology problems than top-line risk: reduced innovation as teams are forced into reactive fire drills that take time away from product development.
If your phone is constantly interrupting your beauty sleep with false alarms, you eventually stop paying attention. And once faith is lost in alerting, you start to assume that every alert is false, and inevitably issues are missed. This phenomenon is known as alert fatigue.
One of the most common reasons for system failures is changes to the underlying infrastructure. Amazon CloudTrail does a great job of recording when actions are taken but a lot of organizations don’t take advantage of it. FireHydrant now includes this data, giving you visibility into changes to your infrastructure while you’re investigating an incident.
Organizations need to continually ramp up and improve their security and resilience to unexpected incidents. But as the number of endpoints, networks, and user interfaces grow exponentially, the task becomes more difficult, and manual incident response management becomes less and less effective.
Going on call and being awakened at a moment’s notice to put out fires when reputation and revenue are on the line is incredibly stressful. And with DevOps teams under increasing pressure to simultaneously release new products faster while ensuring reliability and quality, burnout is a rapidly growing problem. It’s why #HugOps and empathy are becoming so central to the culture of DevOps.
Our founders created PagerDuty with the simple goal of making the lives of on-call developers better—and in doing that, we’ve championed a new way of working, inspired by the DevOps mindset. From that starting point, we’ve evolved our on-call product into a platform for real-time operations that enables our customers to grow from on-call rotations, to incident management and response, to full digital operations management.
Our new app makes it incredibly easy for Zendesk users to escalate customer-reported issues to the proper team, right from the Zendesk UI. Customer service agents can also check on the status of existing alerts without leaving their dashboard. The launch of this app is more critical than ever, as constantly changing customer expectations demand that IT and service companies are high performing and always on.