What Are Speed Tests & How to Run Them (Scheduled & On-Demand) | Obkio NPM Onboarding Series
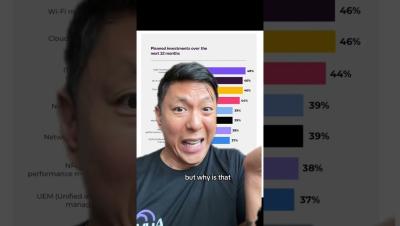
What Are Speed Tests & How to Run Them (Scheduled & On-Demand) Learn how to measure network speed and validate the overall performance of your network with scheduled and on-demand speed tests in Obkio's Network Performance Monitoring app. You can view, schedule and run Speed Tests from the “Speed Tests” tab in Obkio’s app.